Introduction to Probability and Data 수업을 들으며 남긴 노트입니다.
Week1: Designing studies
1. Data Basics
2. Observational Studies & Experiments
3. Sampling and sources of bias
4. Experimental Design
5. Random Sample Assignment
1. Data Basics
* Observations / Variables / Data matrices
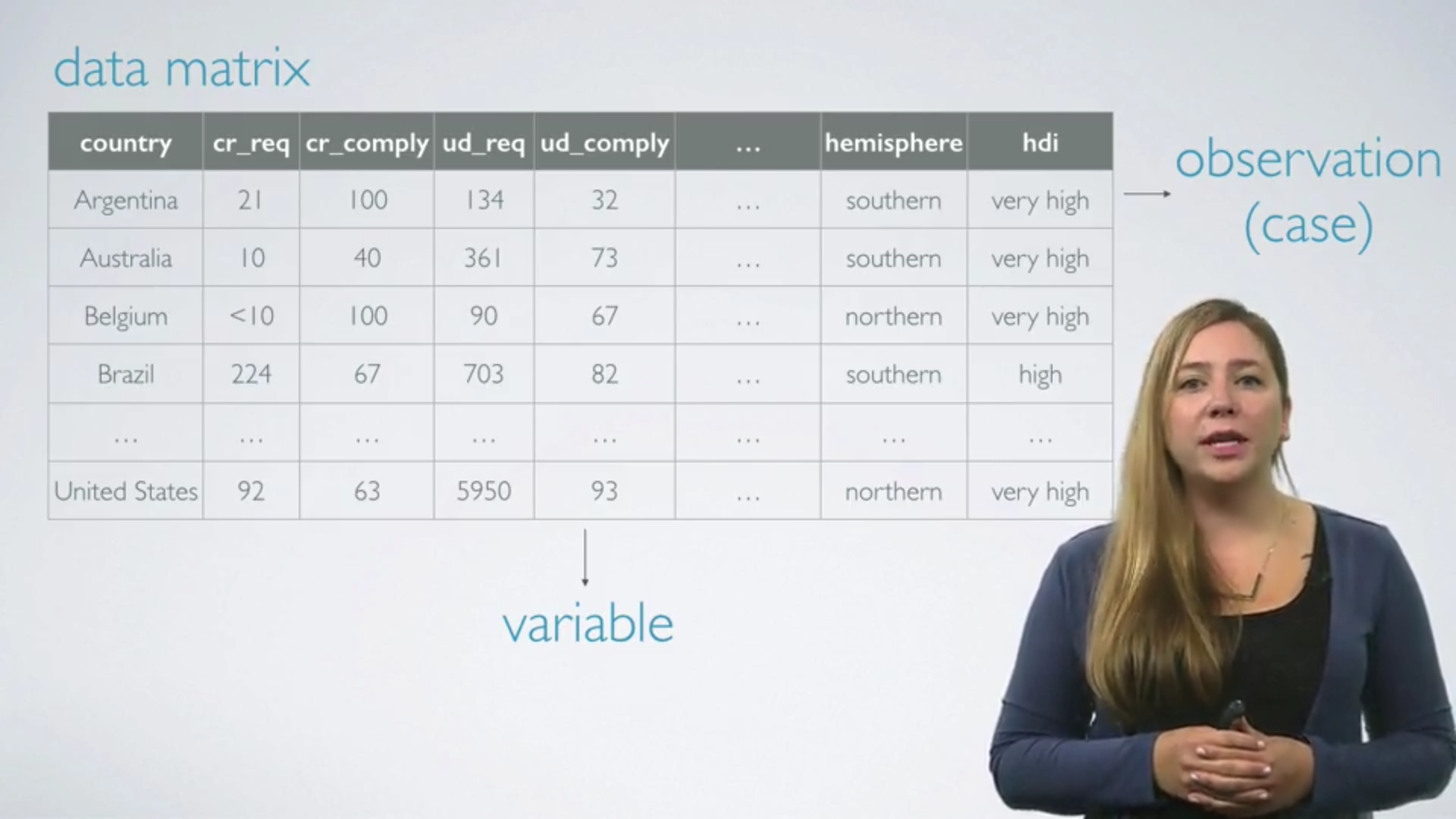
* types of variables
|
all variable |
|||
|
Numerical (quantitative) |
Categorical (qualitative) |
||
|
더하고, 빼고, 평균을 구할 수 있는 수치적 값을 가진다.
take on numerical values sensible to add, subtract, take averages, etc. with these values. |
제한된 수의 서로 다른 범주를 값을 가진다.
take on a limited number of distinct categories can be identified with numbers, but not sensible to do arithmetic operations. |
||
|
Continuous |
Discrete |
Regular Categorical |
Ordinal |
|
주어진 범위 내에서 무한한 실수의 값을 취한다. take on any of an infinite number of values within a given range. |
특정 숫자 값 집합 중 하나를 취합니다. take on one of a specific set of numeric values. |
고유한 순서가 없는 경우 그냥 caregorical 변수라 부른다. (e.g 당신은 아침형인간입니까 저녘형 인간입니까?) |
고유한 상속적 순서가 있는 변수. levels have an inherent ordering. |
-
Continuous Numerical 변수는 보통 측정된 것이다. (e.g. 신장 163.8 cm .. 164.1 cm ...)
-
Count variable은 Discrete 이산형 변수이다.
-
Continuous 변수를 rounding하면 이산형 변수처럼 나타낼 수 있다.
-
Categorical범주형 변수를 숫자로 식별할 수 도 있다. (여성은 0, 남성은 1 과 같이)
-
하지만 Categorical 변수 값으로 산술연산을 하는 것은 적절치 못하다.
2. observational studies and experiments
|
study |
|
|
observational |
experiment |
|
|
-
관측 연구에서 연구자들은 관측 연구에서 연구자들은 데이터가 어떻게 발생하는지 직접 간섭하지 않는 방식으로 데이터를 수집한다.
-
즉, 그들은 단지 관찰한다. 그리고 관측 연구를 기반으로 association를 설립 할 수 있다. 하지만 인과관계를 주장할 수는 없다.
-
association이란 설명변수와 반응변수 간의 상관관계를 말한다. correlation between explanatory and the response variables.
-
관측 연구가 과거의 자료를 사용한다면, 그것은 retrospective study라 한다.
-
반면 연구 도중에 수집 된 데이터를 사용한다면 prospective 연구라고 한다.

-
observational studies와 experiments의 가장 큰 차이점은 Random assignment 이다.
-
대부분의 experiments에서는 random assignment를 사용하고, observational study에서는 사용하지 않는다.
* random assignment?
정기적인 운동과 에너지 수준 사이의 관계를 평가하고 싶을때, 연구를 관측 연구로 또는 실험으로 설계 할 수 있다.
1. 관측 연구에서는 모집단에서 운동을 선택하는 사람들과 그렇지 않은 두 가지 유형의 사람들로 샘플을 추출한다. 그리고 두 그룹의 평균 에너지 수준을 관측해 비교한다.
2. 실험에는 사람들을 무작위로 두 그룹으로 할당한다. (연구 기간 동안 정기적으로 운동을 할 사람들과 그렇지 않은 사람들로)
1과 2의 방식의 차이점은 운동을 할지 안할지에 대한 결정을 실험 대상자가 하느냐, 연구자가 부과하는냐의 차이이다.
The difference is that the decision of whether to work out or not is not left up to the subjects as in the observational study, but is instead imposed by the researcher.
결과적으로 두 그룹 간의 평균 에너지 수준의 의미있는 차이를 발견하더라도 observational study에서는 정기적 운동이라는 attribute가 전적으로 이 차이를 만들어냈다고 말할 수 없다. 이 study에서 통제하지 못한 다른 attribute가 관찰된 차이에 기여했을 수 있기 때문이다.
하지만 random assignment로 인해 실험에서는 결과에 영향을 끼칠 수 있는 variable이 두 그룹에서 거의 동일하게 나타난다. 그렇기때문에 두 그룹의 평균적인 차이를 발견하면, 이 차이를 설명하는 colossal statement를 만들 수 있다.
Those who will regularly work out through the course of the stud and those who will not. The difference is that the decision of whether to work out or not is not left up to the subjects as in the observational study, but is instead imposed by the researcher. At the end, we compare the average energy levels of the two groups based on the observational study even if we find the difference between the average energy levels of these two groups of people, we can't attribute this difference solely to working out. Because there may be other variables that we didn't control for in this study, that contribute to the observed difference. For example, people who are in better shape might be more likely to regularly work out and also have higher energy levels. However, in the experiment, such variables that might also contribute to the outcome are likely equally represented in the two groups due to the random assignment. Therefore, if we find a difference between the two averages, we can indeed make a colossal statement attributing this difference to working out.
* correlation vs causation.
상관관계 vs 인과관계
confounding variables: extraneous variables that affect both the explanatory and the response variable, and that make it seem like there is a relationship between them.
3. Sampling and sources of bias
* census vs a sample
Previously, we mentioned taking a sample from the population, but one might ask,
Q: Wouldn't it be better to just include everyone and "sample" the entire population, in other words, conduct a census?
A:
As you can imagine, conducting a census takes lots of resources, but there are other reasons why this might not be a good idea.
- First, some individuals may be hard to locate or hard to measure, and these people may be different from the rest of the population. For example, in the US Census, illegal immigrants are often not recorded properly, since they tend to be reluctant to fill out census forms, with the concern that this information could be shared with Immigration.
- However, these individuals might possess characteristics different than the rest of the population, and hence not getting information from them might result in very unreliable data from geographical regions with high concentrations of illegal immigrants.
- Another reason why censuses aren't always a good idea, is that populations rarely stand still. Even if you could take a census, the population changes constantly, so it's never really possible to get a perfect measure.
If you think about it, sampling is actually quite natural. Think about something you're cooking. We taste, in other words, we examine a small part of what we're cooking, to get an idea about the dish as a whole.
-
We would never eat a whole pot of soup just to check it's taste after all. When you taste a spoonful of soup and
decide that spoonful you're tasted isn't salty enough, what you're doing is simply exploratory analysis for the sample at hand.
-
If you then generalize and conclude that your entire needs salt, that's making an inference.
-
For your inference to be valid, the spoonful you tasted, your sample, needs to be representative (sample) of your entire pot, your population.
-
If your spoonful comes only from the surface, and the salt is collected at the bottom of the pot, what you tasted is probably not going to be representative of the whole pot. On the other hand, if you first stir the soup thoroughly before you taste, your spoonful will be more likely to be representative of the whole pot.
* sources of bias in studies,
Let's review a few sources of sampling bias.
Convenience sample:
Bias occurs when individuals who are easily accessible, are more likely to be included in the sample.
For example, say you want to find out how people in your city feel about a recent increase in public transportation costs. If you only poll people in your neighborhood, as opposed to a representative sample from the whole city,
tour study would suffer from convenience bias.
Non-response:
This happens if only a non-random fraction of the randomly sampled people respond
to a survey, such that the sample is no longer representative of the population.
For example, say you take a random sample of individuals from your city, and attempt to survey them, but certain segments of the population, say those from a lower socioeconomic status, are less likely to respond to the survey.
Similar sampling bias is called
voluntary response bias:
which occurs when the sample consists of only people who volunteer to respond because they have strong opinions on the issue.
For example, say you place polling machines at all bus stops and metro stations in your city, but only those who choose to do so actually take the time to vote and express their opinion on the recent increase on public transportation costs.
2013년 8월 CNN에서 서방 국가들이 시리아에 개입해야하는지 여부를 묻는 온라인 여론 조사에서 voluntary response bias를 확인 할 수 있다. 이 설문에 답한 사람들은 투표를 해야한다고 강하게 느낀 사람들만 cnn 사이트에 접속해서 투표를 했을 것이므로, 세계시민을 모집단으로 한 representative sample이라고 볼 수 없다. 그래서 이 투표 자체가 과학적이라고 볼 수 없다.
Voluntary response bias clearly exists in online polls like this one from CNN from August 2013, which asked whether the West should intervene in Syria. The people who responded to this poll definitely do not make up a representative sample of the world population, since these are people who happen to have visited cnn.com the day the poll was posted and felt strongly enough to vote. Indeed, the poll results say that this is not a scientific poll for this very reason.
The difference between voluntary response bias and non-response bias:
-
In non-response there is a random sample that is surveyed, but the people who choose to respond are not representative of the sample.
-
In voluntary response there is no initial random sample.
Q.
A retail store considering updates to their credit card policies randomly samples 1000 of their credit card holders to survey on the phone. The phone calls are made during business hours, therefore there is a lower rate of responses from members who work during these hours. What type of bias is this indicative of?
A.
There is an initial random sample, but not everyone in this random sample is reached. Therefore the issue is non-response of the sampled individuals.
* Sampling methods
Let's examine a historical example of bias sample yielding misleading results. In 1936 Landon sought the Republican presidential nomination opposing the reelection of Franklin Delano Roosevelt, commonly referred to as FDR.
A popular magazine of the times, the Literary Digest, polled about 10 million Americans and got responses from about 2.4 million. To put things in perspective, nowadays reliable polls in the US routinely poll about 1,500 people, so this was a huge sample. The poll showed that Landon would likely be the overwhelming winner, and FDR would only get 43% of the votes. In reality, FDR won the election with 62% of the votes. The magazine was completely discredited because of the poll and was soon discontinued.
So, if you have never heard of this magazine, this might be the reason why. But what went wrong?
The magazine had surveyed its own readers, registered automobile owners and registered telephone users. These groups had incomes well above national average of the day. Remember, this was the great depression era, which resulted in lists of voters far more likely to support Republicans, than a truly typical voter of the time. In other words, the sample was not representative of the American population at the time. While The Literary Digest election poll was based on a sample size of 2.4 million, a huge sample, since the sample was biased, it did not yield an accurate prediction.
Going back to the soup analogy, if the soup is not well stirred, it doesn't matter how large a spoon you have, it will still not taste right. If the soup is well stirred, a small spoon will suffice to test the soup.
Now that we have a good idea of why we might want to sample, and why it's important for our sample to be representative of the population,
simple random sampling(SRS),
모집단 내의 모든 case를 대상들이 같은 확률로 선택될 수 있도록 한다.
we randomly select cases from the population, such that each case is equally likely to be selected. This is similar to randomly drawing names from a hat.
stratified sampling,
모집단을 strata라는 균질한 그룹으로 나눈다. 각 stratum 내에서 무작위로 샘플을 추출한다.
we first divide the population into homogenous groups called strata, and then randomly sample from within each stratum. For example, if we wanted to make sure both genders are equally represented in a study, we might divide the population first into males and females, and then randomly sample from within each group.
cluster sampling,
모집단을 클러스터로 나눠 무작위로 몇개의 클러스터를 샘플링한다. 그리고 샘플링된 클러스터에서 발견된 모든 observation을 sample에 포함한다.
we divide the population into clusters, randomly sample a few clusters, and then sample all observation within these clusters.
-
strata와 stratified sampling과 달리 clusters은 자기 자신 내에서 이질적인 것을 말한다 각각의 cluster는 다른 cluster와 유사하므로 그냥 몇개의 클러스터에서 샘플링을 수행하면 된다.
The clusters, unlike strata and stratified sampling, are heterogeneous within themselves, and each cluster is similar to another, such that we can get away with just sampling from a few of the clusters.
multistage sampling,
모집단을 클러스터로 나눠 무작위로 몇개의 클러스터를 샘플링한다. 그리고 샘플링된 클러스터에서 발견된 observation에 대해 무작위로 샘플링한다.
In multistage sampling, adds another step to cluster sampling. Just like in cluster sampling, we divide the population into clusters, randomly sample a few clusters, and then we randomly sample observations from within these clusters. For example, one might divide a city into geographic regions that are on average similar to each other, and then sample randomly a few of these regions, go to these randomly picked regions, and then, sample a few people from within these regions. This avoids the need to travel to all of the regions in the city.
-
Usually, we use cluster sampling and multistage sampling for economical reasons.
4. Experimental Design
we will discuss principles of experimental design and learn some experimental design terminology.
* Principles of experimental design
|
Control |
Randomize |
Replicate |
Block |
|
compare the treatment of interest to a control group |
randomly assign subjects to treatments |
collect a sufficiently large sample, or replicate the entire study |
block for variables known or suspected to affect the outcome |
Lets discuss blocking a bit more, we would like to design and experiment to investigate if energy gels make you run faster. The treatment group gets the energy gel, the control group does not get any energy gel. It is suspected that energy gels might effect pro and amateur athletes differently therefore we block for pro status.
To do so, we divide our sample into pro and amateur athletes, and then, we randomly assign pro and amateur athletes to treatment and control groups, therefor, pro and amateur athletes are equally represented in the resulting treatment and control groups.
This way, if we do find a difference in running speed between the treatment and control groups we will be able to attribute it to the treatment, the energy gel, and can be assured that the difference isn't due to pro status since both pro and amateur athletes were equally represented in the treatment and control groups.
* blocking variable vs explanatory variable?
- Explanatory variables also sometimes called factors, are conditions we can impose on our experimental units.
- Blocking variables are characteristics that the experimental units come with, that we would like to control for.
- Blocking is basically like stratifying,
- expect used in experimental settings when randomly assigning as opposed to when sampling.
5. Random Sample Assignment
we will discuss random sampling and random assignment, two concepts that sound similar, but serve quite different purposes in study design.
Random Sampling
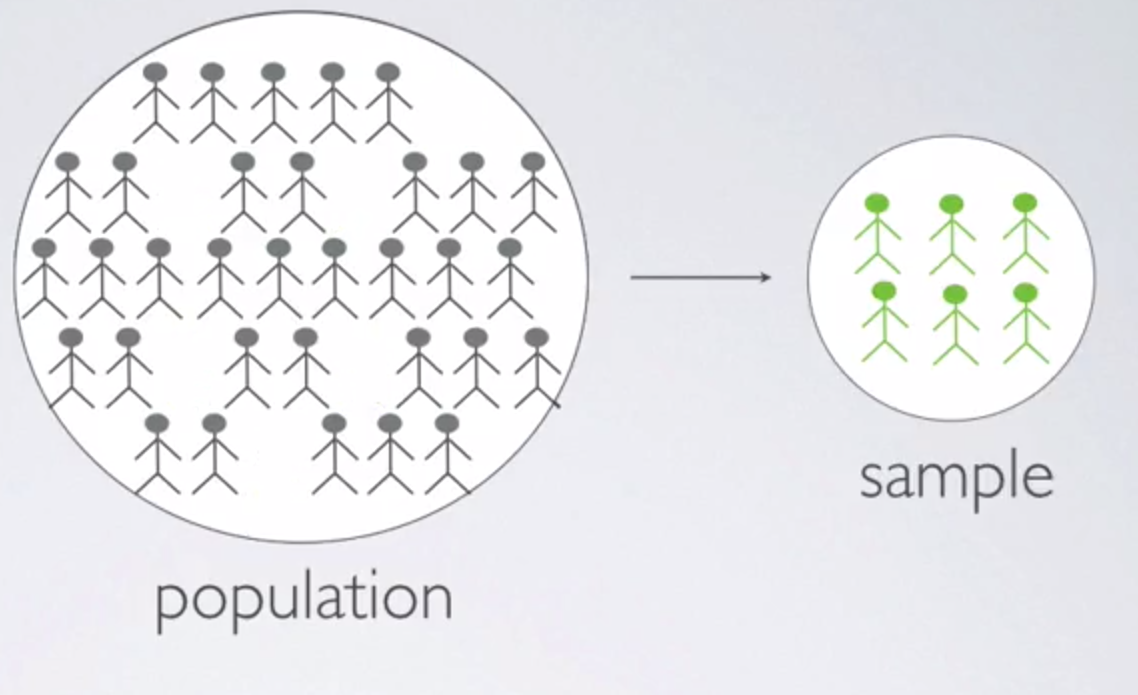
- Random sampling occurs when subjects are being selected for a study.
- If subjects are selected randomly from the population, then each subject in the population is equally likely to be selected, and the resulting sample is likely representative of the population.
- Therefore the study's results are generalizable to the population at large.
Random assignment

- Random assignment occurs only in experimental settings, where subjects are being assigned to various treatments.
- Taking a close look at our sample, we usually see that the subjects exhibit slightly different characteristics from one another.
- Through a random assignment, we ensure that these different characteristics are represented equally in the treatment and control groups.
- This allows us to attribute any observed difference between the treatment and control groups, to the treatment being observed on the subjects, since otherwise these groups are essentially the same.
- In other words, random assignment allows us to make causal conclusions based on the study.
example,
Suppose you want to conduct a study, evaluating whether people read serif fonts or sans serif, or in other words, without serif fonts faster. Note that serifs are this small jacketed pieces at the ends of each character.
Ideally, he would first randomly subjects for your study from your population. Then, you assigned the subjects in your sample to two treatment groups. One, where they read some text in serif font, and the other where they read the same text in sans serif font. Through random assignment, we ensure that other factors that may be contributing to reading speed indicated here with the different colors or the subjects. For example, fluency or how often the subject reads for leisure, are represented equally in the two groups.
We call such variables confounders, or confounding variables. In this setting, if we observe any difference between the average reading speeds of the two groups, we can actually attribute it to the actual treatment, the font type, and know that it's likely not due to a confounding variable.
So to recap, sampling happens first, and assignment happens second.

- A study that employs random sampling and random assignment, can be used to make causal conclusions, and these conclusions can be generalized to the whole population.
- This would be an ideal experiment, but site studies are usually difficult to carry out,
- especially if the experimental units are humans, since it may be difficult to randomly sample people from the population, and then impose treatments on them. This is why most experiments recruit volunteer subjects. You may have seen ads for these on a university campus, or in a newspaper.
- Such human experiments that rely on volunteers employ random assignment, but not random sampling.
- These studies can be used to make causal conclusions, but the conclusions only apply to the sample, and the results cannot be generalized.
- A study that uses no random assignment, but does use random sampling, is your typical observational study.
- Results can only be used to make correlation statements, but they can be generalized to the population at large.
- A final type of study, one that doesn't use random assignment or random sampling, can only be used to make correlational statements, and these conclusions are not generalizable. This is an un-ideal observational study.
* Terminology
Placebo:
fake treatment, often used as the control group for medical studies.
Placebo effect: when the experimental unit show improvement simply because they believe they're receiving special treatment.
Blinding: when experimental units do not know whether they are in the control or the treatment groups.
Double-blind study: one where both the experimental units and the researchers do not know who is in the control and who is in the treatment group.
| population - 모집단 sample - 표본 sampling - 표본 추출 observational study - 관찰 연구 experiment - 실험 confounding variable - 교란변수 correlation - 상관관계 causation - 인과관계 bias - 편향 census - 인구 조사 simple random sample (SRS) - 단순임의표본 stratified sample - 층화표본 explanatory variable - 설명변수 response varaible - 반응변수 blocking variable - 구획변수 control group - 통제집단 numerical (quantitative) variable - 수치형 (양적) 변수 categorical (qualitative) variable - 범주형 (질적) 변수 continuous - 연속형 discrete - 이산형 ordinal - 순서형 scatterplot - 산점도 outlier - 이상치 histogram - 도수분포표 skewness - 왜도 kurtosis - 첨도 mean - 평균 median - 중간값 mode - 최빈값 range - 범위 variance - 분산 standard deviation - 표준편차 quantile - 사분위수 robustness - 강건성 transformation - 변환 |

