Algorithms, Part 1: week1 Lecture note:
I implemented codes in python3.
Steps to developing a usable algorithm.
Model the problem. ( try to understand the main elements of the problem that needs to be solved. )
해결해야하는 요소를 이해하고 문제를 모델링한다.
Find an algorithm to solve it.
문제를 해결할 수 있는 알고리즘을 알아낸다.
Fast enough? Fits in memory?
충분히 빠른지, 메모리 사용량은 적당한지 고려한다.
If not, figure out why.
아니라면, 왜 그런지 알아낸다.
Find a way to address the problem.
문제를 해결할 수 있는 방법을 찾아낸다.
Iterate until above things are satisfied.
위의 요소들이 만족될때까지 반복.
overview
Lecture1:
Union−Find. We illustrate our basic approach to developing and analyzing algorithms by considering the dynamic connectivity problem. We introduce theunion−find data type and consider several implementations (quick find, quick union, weighted quick union, and weighted quick union with path compression). Finally, we apply the union-find data type to the percolation problem from physical chemistry.
Dynamic connectivity
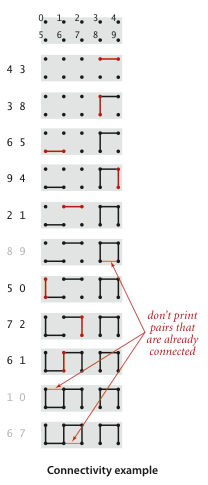
- symmetric(순차): If q is connected to p, then p is connected to q.
q가 p와 연결되었다면, p도 q와 연결된다.
- transitive(전이): If q is connected to p and p is connected to r, then q is connected to r.
q 가 p와 연결되어 있고 p가 r과 연결되었다면, q도 r과 연결된다.
- reflexive(재귀): p is connected to p.
모든 노드는 자기 자신과 연결되어있다.
Goal
Write a program get 2 integers from a user and return True if they are connected( else return False).
2개의 정수를 입력받고 해당 노드들이 연결되어있으면 True, 연결되어있지 않으면 False를 반환하는 프로그램을 작성한다.
Quick find
data structure: simply an integer array id[] of size N.

class QuickFind():
def __init__(self, N):
# Set id of each object to itself(N array accesses)
self.id = list()
for i in range(N):
self.id += [i]
# Check whether p and q are in the same component(2 array accesses)
def connected (self,p,q):
return self.id[p] == self.id[q]
# Change all entries with id[p](at most 2N + 2 array accesses)
def union (self, p, q):
pid = self.id[p]
qid = self.id[q]
for j in range(len(self.id)):
if self.id[j]==pid: self.id[j] = qid
|
algorithm |
initialize |
union |
find |
|
quick-find |
N |
N |
1 |
This is called eager algorithm.
It is easy to implement, but It takes O(n^2).
* The union operation is too expensive. *
In particular, if you just have N union commands on N objects.
They're either connected or not then that will take quadratic time in squared time.
And quadratic time is much to slow. we can't accept quadratic time algorithms for large problems.
The reason is they don't scale. As computers get faster and bigger, quadratic algorithms actually get slower.
A very rough standard, say, for now, is that people have computers that can run billions of operations per second, and they have billions of entries in main memory.
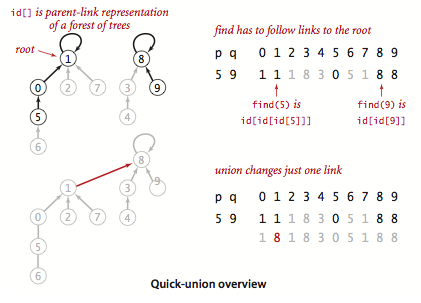
Quick Union
data structures: tree
class QuickUnion():
def __init__(self, N):
# Set id of each object to itself(N array accesses)
self.id = list()
for i in range(N):
self.id += [i]
# Check parent pointers until reach root (depth or i array accesses)
def root(self, n):
while n != self.id[n]:
n = self.id[n]
return n
# Check if p and q have a same root (depth of p and q array accesses)
def connected (self,p,q):
return self.root(p) == self.root(q)
# Change root of p to point to root q (depth of p and q array accesses)
def union (self, p, q):
i = self.root(p)
j = self.root(q)
self.id[i] = j
This is called a lazy approach
it is faster than quick find, but also slower.
The tree could be too tall. (Then find operation gonna be too expensive.)
(worst case)
|
algorithm |
initialize |
union |
find |
|
quick-find |
N |
N |
1 |
|
quick-union |
N |
N |
N |
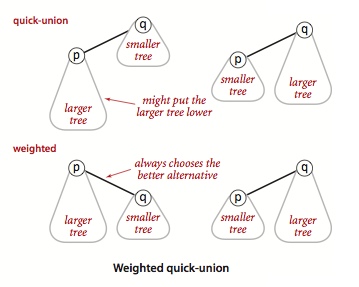
Improvement 1: Weighted quick union
Modify quick-union to avoid tall trees.
Keep track of the size of each tree (number of objects).
Balance by linking root of a smaller tree to the root of a larger tree.
class WeightedQuickUnion():
def __init__(self, N):
# Set id of each object to itself(N array accesses)
# extra array sz[i] to count number of objects in the tree rooted at i.
self.id = list()
for i in range(N):
self.id += [i]
self.sz = [1]*len(self.id)
# Check parent pointers until reach root (depth or i array accesses)
def root(self, n):
while n != self.id[n]:
n = self.id[n]
return n
# Check if p and q have a same root (depth of p and q array accesses)
def connected (self,p,q):
return self.root(p) == self.root(q)
# Link root of smaller tree to root of larger tree
def union (self, p, q):
i = self.root(p)
j = self.root(q)
if i == j: return
if self.sz[i] < self.sz[j]:
self.id[i] = j
self.sz[j] += self.sz[i]
else:
self.id[j] = i
self.sz[i] += self.sz[j]
algorithm | initialize | union | find |
quick-find | N | N | 1 |
quick-union | N | N | N |
weighted quick-union | N | log N | log N |
Improvement 2: Path compression
class PathCompression_QU():
def __init__(self, N):
# Set id of each object to itself(N array accesses)
# extra array sz[i] to count number of objects in the tree rooted at i.
self.id = list()
for i in range(N):
self.id += [i]
self.sz = [1]*len(self.id)
# Check parent pointers until reach root (depth or i array accesses)
def root(self, n):
while n != self.id[n]:
self.id[n] = self.id[self.id[n]]
n = self.id[n]
return n
# Check if p and q have a same root (depth of p and q array accesses)
def connected (self,p,q):
return self.root(p) == self.root(q)
# Link root of smaller tree to root of larger tree
def union (self, p, q):
i = self.root(p)
j = self.root(q)
if i == j: return
if self.sz[i] < self.sz[j]:
self.id[i] = j
self.sz[j] += self.sz[i]
else:
self.id[j] = i
self.sz[i] += self.sz[j]
algorithm |
worst-case time |
quick-find |
M N |
quick-union |
M N |
weighted quick-union |
N + M log N |
quick-union + path compression |
N + M log N |
weighted quick-union + path compression |
N + M lg* N |